Lab
이 Lab에서는 LangGraph, OpenAI API, 그리고 Kakao 장소 검색 API를 활용하여 간단한 장소 검색 챗봇을 만들어봅니다.
1단계: 개발 환경 설정 및 API 키 준비
실습을 시작하기 전에 필요한 파이썬 패키지를 설치하고 API 키를 설정해야 합니다.
- 필요 패키지:
langgraph,langchain-openai,python-dotenv,requests.
터미널에서 다음 명령어를 실행하여 설치합니다:pip install langgraph langchain-openai python-dotenv requests이 패키지들은 LangChain/LangGraph 프레임워크, OpenAI의 LLM 연동, .env 파일 로딩, 그리고 HTTP 요청 등을 위해 사용됩니다.
OpenAI API 키: OpenAI의 GPT 모델을 사용하기 위해 API 키를 발급받아 환경변수
OPENAI_API_KEY에 저장하거나,
.env파일에OPENAI_API_KEY=<your_key>형태로 기록하세요.Kakao REST API 키: Kakao 지도/로컬 API를 사용하기 위해 Kakao Developers에서 REST API 키를 발급받아야 합니다.
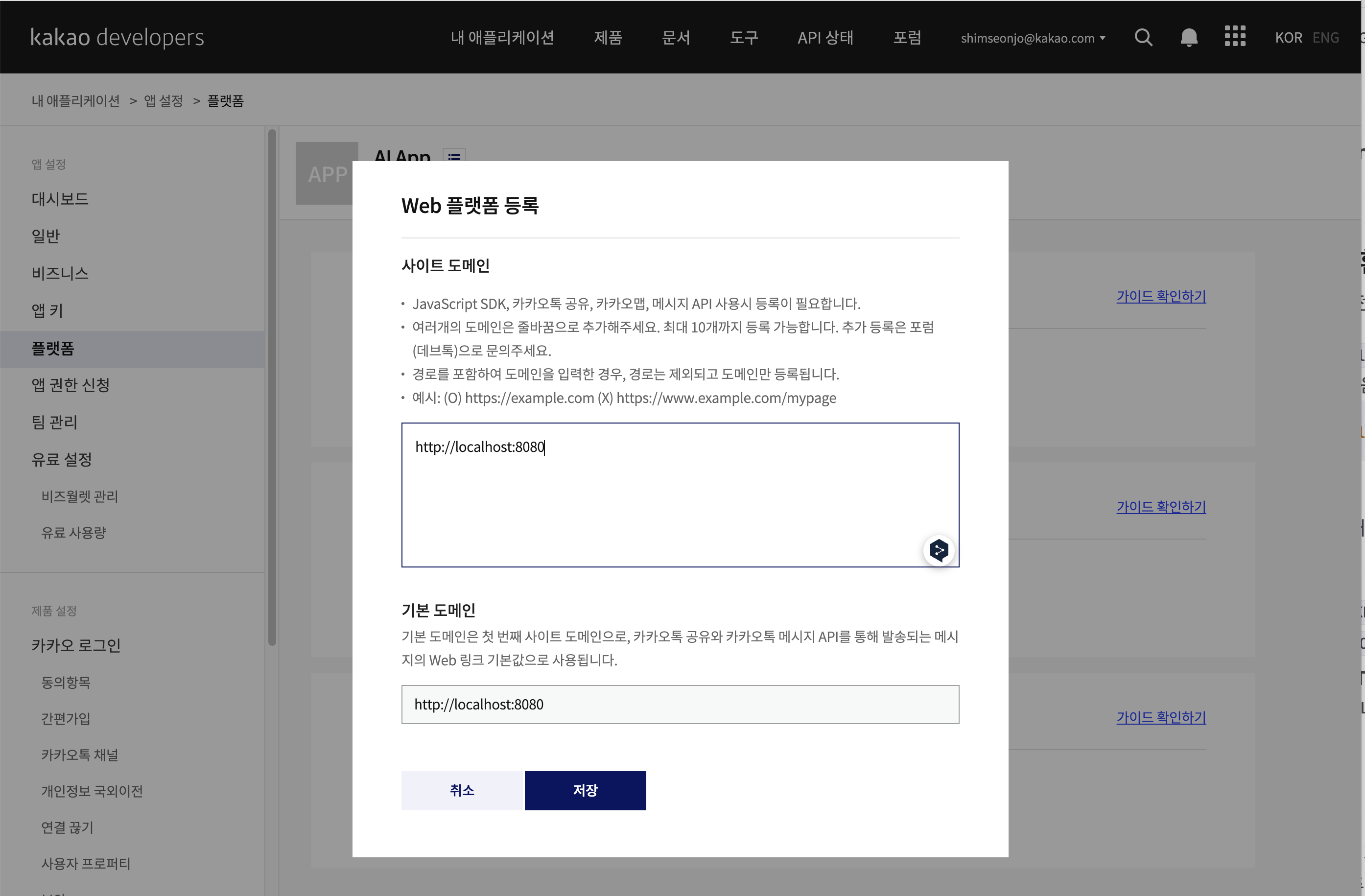
발급받은 키를 환경변수KAKAO_API_KEY에 저장하거나.env파일에KAKAO_API_KEY=<your_key>형태로 추가하세요.내 애플리케이션 - 애플리케이션 추가  REST API키 복사해서 .env 파일에 추가  플렛폼 메뉴의 web 항목에 `Web 플랫폼 등록`클릭 http://localhost:8080 입력,
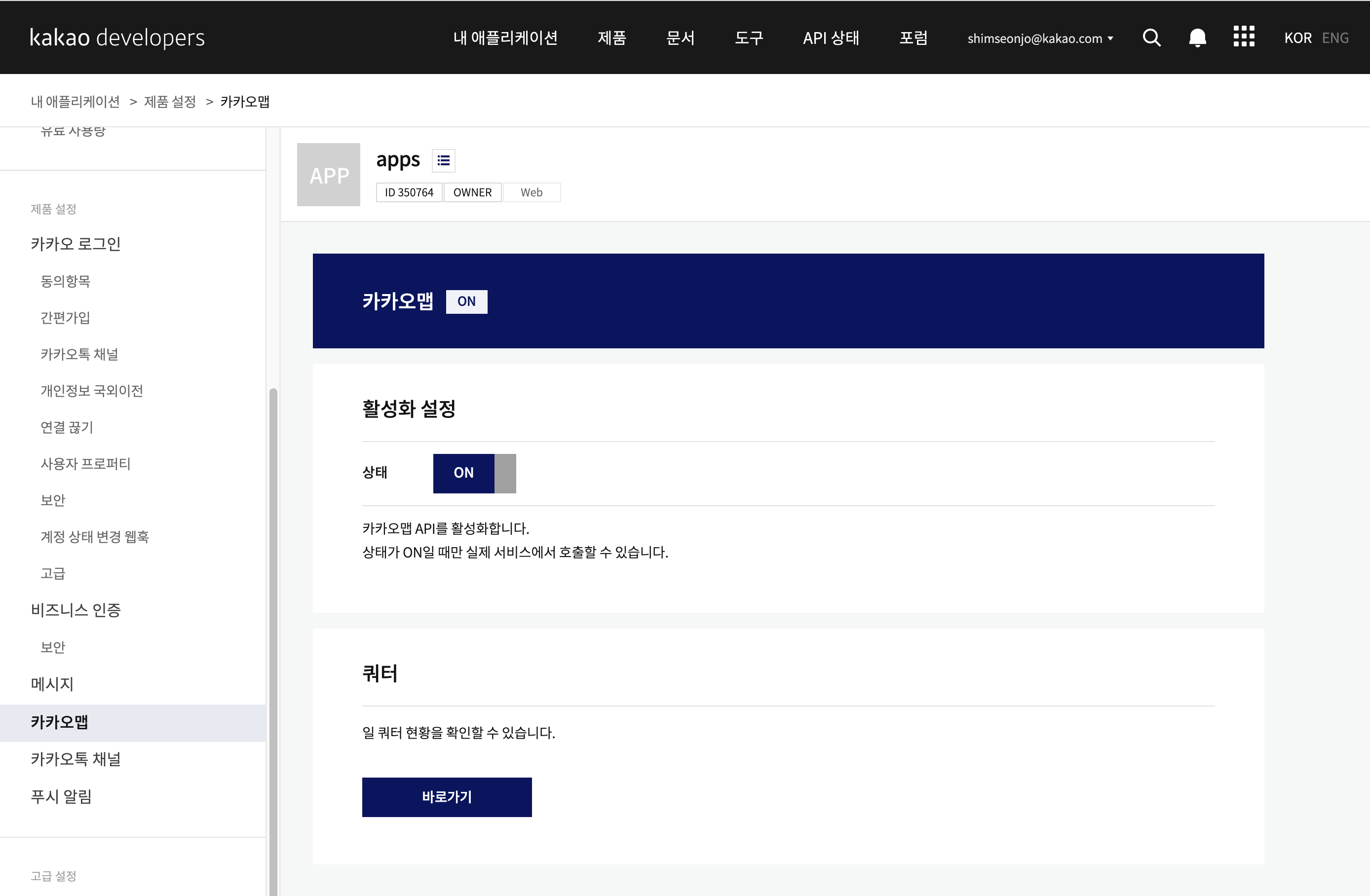
카카오맵 메뉴에 활성화 버튼 체크함.
🔑 노트:
.env파일을 사용하면python-dotenv가 자동으로 환경변수를 로드해줍니다. 이 파일은 프로젝트 루트에 두고 위 두 키를 포함시켜 주세요. 나중에 코드에서load_dotenv()를 호출하면 이 파일의 내용이 적용됩니다.
설정이 완료되면 파이썬 인터프리터나 Jupyter 노트북을 열고 다음 단계를 진행합니다.
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from typing_extensions import TypedDict
from typing import Annotated, List
from dotenv import load_dotenv
import os
load_dotenv()
openai_model = os.getenv("OPENAI_MODEL", "gpt-4.1-nano")
KAKAO_API_KEY = os.getenv("KAKAO_API_KEY")
# OpenAI 챗 모델 초기화
llm = ChatOpenAI(model="gpt-4.1-nano")
2단계: 상태(State) 및 데이터 구조 정의
이 챗봇은 대화 상태를 유지하며 동작합니다.
우선 상태를 표현할 클래스와 장소 정보 구조를 정의해보겠습니다:
from typing import List, Optional
from typing_extensions import TypedDict
# 장소 정보를 담는 TypedDict 정의
class KakaoPlace(TypedDict):
name: str
address: str
url: str
# 대화 상태를 담는 TypedDict 정의
class State(TypedDict):
# 대화 메시지 목록 (Human, AI, Tool 메시지들이 순서대로 저장됨)
messages: List # 실제 타입은 아래에서 Annotated를 통해 정의 예정
# 장소 검색용으로 추출된 키워드 (초기에는 없을 수 있음)
search_query: Optional[str]
# Kakao API로 찾은 장소 결과 목록 (초기에는 없을 수 있음)
search_results: Optional[List[KakaoPlace]]
KakaoPlace: Kakao 장소 검색 결과 하나를 표현하는 딕셔너리 타입입니다.name,address,url세 가지 문자열 정보를 가집니다.State: 챗봇의 전체 상태를 나타내는 딕셔너리 타입입니다.messages에는 현재까지 오간 모든 메시지가 리스트로 저장됩니다.search_query는 (필요하면) 사용자 요청으로부터 추출한 검색 키워드를 저장하고,search_results는 Kakao API에서 얻은 장소 리스트를 저장합니다.Optional[str]등의 표기를 통해 해당 값이 없을 수도 있음을 표시했습니다 (None일 수 있음).
이렇게 타입을 정의하면, 이후 그래프를 설정할 때 State 구조를 사용하여 상태 관리가 일관되게 이루어집니다. 이제 LangGraph에서 messages 필드에 대해 특수 설정을 해주겠습니다. messages는 대화 메시지들의 리스트인데, 여기에 새 메시지를 추가할 때 자동으로 이어붙여지도록 LangGraph의 도우미를 사용할 수 있습니다.
from langgraph.graph.message import add_messages
from langchain_core.messages import BaseMessage
# State 클래스 수정: messages에 Annotated 적용
from typing import Annotated
class State(TypedDict):
messages: Annotated[List[BaseMessage], add_messages]
search_query: Optional[str]
search_results: Optional[List[KakaoPlace]]
Annotated[List[BaseMessage], add_messages]: LangGraph에서 제공하는 기능으로, 상태의messages리스트를 다룰 때 새 메시지를 누적으로 추가(append)하는 동작을 자동으로 해줍니다.BaseMessage는 모든 메시지(Human, AI, Tool 메시지)의 베이스 클래스입니다. 이 설정을 통해 그래프 노드가{"messages": [새로운메시지]}형태로 반환하더라도, 기존 메시지 리스트에 새 메시지가 append되도록 해줍니다.- 이렇게 설정하지 않으면, 매번 상태 반환 시 전체 메시지 목록을 관리해야 하는 불편이 있습니다.
add_messages덕분에 상태 관리가 쉬워집니다.
이제 우리의 상태 구조 정의가 완료되었습니다. 다음 단계에서는 실제로 메시지를 주고받는 LLM과 외부 도구들을 정의하겠습니다.
3단계: LLM 모델 초기화하기
이 챗봇의 “두뇌”인 언어 모델(LLM)을 설정합니다. LangChain의 ChatOpenAI 클래스를 사용하여 OpenAI의 GPT 모델을 불러오겠습니다.
from langchain_openai import ChatOpenAI
# 환경 변수에서 API 키 로드 (OpenAI API와 Kakao API 키)
import os
from dotenv import load_dotenv
load_dotenv() # .env 파일의 환경변수를 불러옴
# OpenAI 챗 모델 초기화
llm = ChatOpenAI(model="gpt-4o-mini")
ChatOpenAI: LangChain에서 OpenAI의 ChatCompletion API를 래핑한 클래스입니다.model파라미터에 사용할 모델명을 지정합니다..env파일에OPENAI_API_KEY가 설정되어 있다면load_dotenv()로 불러온 후os.getenv("OPENAI_API_KEY")등을 통해 자동으로 OpenAI API 키를 사용합니다.ChatOpenAI는 내부적으로 해당 키를 찾아 API 호출을 준비합니다.
LLM이 초기화되었지만, 아직 이 LLM은 도구를 모릅니다. 다음 단계에서 도구(툴) 함수를 정의하고 LLM과 연결해보겠습니다.
🔧 Tip: 만약 OpenAI API 대신 다른 모델을 쓰고 싶다면, LangChain의 다른 wrapper 클래스를 사용할 수 있습니다. 예를 들어
ChatAnthropic(Anthropic의 Claude),ChatGooglePalm(Google PaLM) 등이 있습니다. 본 실습에서는 OpenAI GPT를 기준으로 진행합니다.
4단계: 키워드 추출 도구 정의하기
첫 번째 도구는 키워드 추출 기능입니다. 사용자 입력 문장에서 검색에 적합한 키워드만 뽑는 역할을 하는 함수를 만들어보겠습니다. 이 함수는 LLM의 힘을 빌려 구현합니다 (즉, LLM에게 “이 문장에서 키워드만 추려줘”라고 요청하는 방식).
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
# 키워드 추출 도구 함수 정의
@tool
def extract_keyword(user_request: str) -> str:
"""사용자 요청에서 장소 검색을 위한 짧고 명확한 키워드를 추출합니다."""
# 키워드 추출을 위한 프롬프트 작성
prompt = (
"다음 요청에서 장소 검색에 사용할 키워드를 한 문장으로 추출해줘.\n"
"- 키워드는 띄어쓰기로 구분된 한 문장이어야 해.\n"
"- 다른 설명은 하지 말고 키워드만 알려줘.\n\n"
f"요청: '{user_request}'"
)
# LLM에게 프롬프트 전달하여 응답 받기
response = llm.invoke([HumanMessage(content=prompt)])
# 응답에서 키워드 추출 (따옴표나 공백 제거)
keyword = response.content.strip().strip('"').strip("'")
return keyword
@tool데코레이터: 이 함수를 LangGraph에서 호출 가능한 도구로 등록합니다. 이제 LLM이extract_keyword라는 도구를 쓸 수 있게 됩니다.- 함수 인자
user_request: str: 사용자 질문 문장이 들어옵니다. - 프롬프트
prompt: LLM에게 한국어 지시를 합니다. 사용자 요청(user_request)이 주어지면, 그 안에서 검색 키워드를 뽑아 달라고 요구합니다. 조건으로 키워드는 한 문장(phrase)으로만 주고, 부가 설명은 하지 말라고 명시했습니다. llm.invoke([HumanMessage(content=prompt)]): 우리 LLM (ChatOpenAI 객체)에 HumanMessage를 전달하여 실행합니다.HumanMessage는 마치 사용자가 LLM에게 프롬프트 내용을 말한 것처럼 맥락을 제공합니다. LLM은 이 메시지를 보고 답변을 생성합니다.response.content: LLM이 출력한 답변 텍스트입니다. 여기에 키워드가 들어있을 것으로 기대합니다. 혹시 모를 앞뒤 공백이나 따옴표를 제거하여keyword변수에 저장합니다.return keyword: 최종 추출된 키워드 문자열을 반환합니다.
이제 extract_keyword 함수가 도구로 정의되었고, 내부에서 llm.invoke를 사용하므로 LLM을 미리 초기화해 둬야 함을 알 수 있습니다. (우리는 3단계에서 LLM을 초기화했으므로 준비 완료입니다.)
예시: 만약 user_request가 "서울에서 분위기 좋은 카페 찾아줘"였다면, LLM은 이 프롬프트에 따라 "서울 분위기 좋은 카페" 정도의 키워드를 추출하여 반환할 것입니다.
5단계: Kakao 장소 검색 도구 정의하기
두 번째 도구는 카카오 장소 검색 API를 호출하는 기능입니다. 앞 단계에서 추출한 키워드를 입력받아 실제 웹 API를 호출하고, 결과를 가공하여 반환합니다.
import requests # HTTP 요청을 위해 필요
@tool
def kakao_place_search(query: str) -> list[KakaoPlace]:
"""카카오 장소 검색 API를 사용하여 장소를 검색합니다."""
# Kakao API 요청을 위한 URL과 헤더, 파라미터 설정
url = "https://dapi.kakao.com/v2/local/search/keyword.json"
headers = {"Authorization": f"KakaoAK {os.getenv('KAKAO_API_KEY')}"}
params = {"query": query, "size": 5}
# API 호출
response = requests.get(url, headers=headers, params=params)
data = response.json().get("documents", [])
# 필요한 정보만 추출하여 KakaoPlace 리스트 구성
results: list[KakaoPlace] = []
for place in data:
results.append({
"name": place.get("place_name", ""),
"address": place.get("address_name", ""),
"url": place.get("place_url", "")
})
return results
@tool: 이 함수도 LLM이 사용할 수 있는 도구로 등록됩니다. 이름은 함수명을 따르므로 “kakao_place_search”로 인식됩니다.query: str: 검색할 키워드 문자열을 받습니다. 보통extract_keyword의 반환값이 이 자리에 들어가겠죠.url: Kakao 로컬 API의 키워드 검색 엔드포인트 URL입니다.headers: Kakao API 키를 헤더에 넣습니다.os.getenv('KAKAO_API_KEY')로 환경변수에서 키를 불러옵니다. (load_dotenv()를 했으므로 .env에서 읽어왔을 것입니다.)"KakaoAK <REST_API_KEY>"형식으로 작성해야 합니다.params:query파라미터에 검색어를 넣고,size를 5로 하여 결과 5개만 요청합니다. (원한다면 size를 늘리거나 줄일 수 있습니다.)requests.get(...): HTTP GET 요청을 보냅니다. Kakao API는 비교적 빠르게 응답을 줄 것이고, 인터넷 연결이 필요합니다.response.json().get("documents", []): 응답을 JSON으로 파싱하고, 그 중"documents"리스트를 추출합니다. Kakao 장소 API는 검색 결과를 documents 배열로 담아주는데, 각 원소가 장소 정보 딕셔너리입니다.results리스트를 만들어, 각place딕셔너리에서 우리가 필요한 정보만 빼서 새 딕셔너리를 만들어 추가했습니다.place_name,address_name,place_url필드를 가져옵니다. (키가 없을 경우를 대비해.get(..., "")형태로 기본값을 빈 문자열로 처리)- 반환값은
results리스트입니다. 이는KakaoPlace타입의 딕셔너리들을 담고 있으므로, LangGraph의 State에 맞게List[KakaoPlace]형식으로 적합합니다.
이제 키워드 추출과 장소 검색 두 가지 도구가 준비되었습니다. 다음으로는 LLM과 이 도구들을 연결하고, 대화 흐름을 제어하는 LangGraph 그래프를 구축해보겠습니다.
6단계: LangGraph로 대화 흐름 그래프 만들기
LangGraph의 StateGraph를 사용하여, 챗봇의 대화 동작을 표현하는 그래프를 만들어봅니다. 우리 시나리오에서는 두 개의 노드가 필요합니다:
- “chatbot” 노드: LLM이 현재까지의 메시지를 보고 다음 메시지를 만들어내는 역할.
- “tools” 노드: LLM이 요청한 도구를 실제 실행하는 역할.
또한 노드 전이(Edge)로는:
- chatbot -> tools: LLM이 도구 사용을 원할 때만 넘어가는 조건부 경로.
- tools -> chatbot: 도구 사용 후 다시 LLM으로 돌아오는 경로 (항상 이동).
이 구조를 코드로 구현해보겠습니다:
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
# 6-1: 각 노드의 동작 정의
def chatbot_node(state: State):
"""LLM이 현재 메시지들을 보고 다음 응답(또는 도구 요청)을 생성하는 노드"""
# state["messages"]에는 대화의 모든 메시지가 있음 (마지막이 사용자의 최신 질문)
ai_response = llm_with_tools.invoke(state["messages"])
# 새로 생성된 AI의 응답 메시지만 돌려주면, Annotated add_messages로 자동 추가됨
return {"messages": [ai_response]}
# ToolNode 생성 (우리가 정의한 tools 리스트 사용)
tools = [extract_keyword, kakao_place_search] # 도구 리스트 준비
llm_with_tools = llm.bind_tools(tools) # LLM에 도구 결합
tool_node = ToolNode(tools) # ToolNode 인스턴스 생성
# 6-2: 그래프 초기화 및 노드 추가
graph_builder = StateGraph(State) # 우리 State 타입에 맞는 그래프 생성
graph_builder.add_node("chatbot", chatbot_node) # "chatbot" 노드 추가
graph_builder.add_node("tools", tool_node) # "tools" 노드 추가
# 6-3: 노드 사이의 엣지(전이) 정의
graph_builder.add_conditional_edges("chatbot", tools_condition)
graph_builder.add_edge("tools", "chatbot")
# 시작 지점 지정 및 그래프 컴파일
graph_builder.set_entry_point("chatbot")
graph = graph_builder.compile()
chatbot_node함수: 우리 대화의 핵심 함수입니다.state: State를 받아서 LLM (llm_with_tools)으로 현재까지의 메시지를 모두 넘겨 다음 응답을 생성합니다. 여기서llm_with_tools를 사용하기 때문에, LLM이 응답 중에 도구를 호출하는 행동이 자동 처리됩니다. 이 함수는 반환값으로{"messages": [ai_response]}딕셔너리를 주는데, 이것은 곧 상태 업데이트 시messages리스트에 새로운 AI 응답을 추가하는 효과를 갖습니다.tools = [extract_keyword, kakao_place_search]: 우리가 만든 두 도구 함수를 리스트에 담았습니다.llm_with_tools = llm.bind_tools(tools): LLM 객체에 도구를 바인딩하여, 이 새로운 객체를 통해 LLM이 도구를 쓸 수 있게 합니다.tool_node = ToolNode(tools): LangGraph에서 제공되는ToolNode클래스를 사용해 도구 실행 전용 노드를 하나 생성합니다. 여기에도 동일한 도구 리스트를 넘겨, 이 노드가 호출되면 해당 도구들을 실제로 실행할 수 있도록 합니다.graph_builder = StateGraph(State): 우리의 State 구조를 기반으로 그래프 빌더를 만듭니다.add_node("chatbot", chatbot_node): “chatbot”이라는 이름으로 위에서 정의한 함수를 노드로 추가합니다.add_node("tools", tool_node): “tools” 이름으로 ToolNode를 추가합니다.add_conditional_edges("chatbot", tools_condition): 조건부 엣지를 추가합니다. 이 한 줄로, “chatbot” 노드 실행 후에tools_condition함수가 상태를 검사하여 True/False 분기를 결정합니다.tools_condition은 기본적으로 LLM이 도구를 호출했는지를 판단합니다. True이면 자동으로 “tools” 노드로 가는 엣지가 추가되고, False이면 “END” (종료)로 가는 엣지가 추가됩니다.add_edge("tools", "chatbot"): 일반 엣지를 추가합니다. “tools” 노드가 끝나면 무조건 “chatbot” 노드로 돌아가도록 연결합니다. 이로써, 도구 사용이 끝나면 다시 LLM이 이어서 응답을 생성하는 루프가 형성됩니다.set_entry_point("chatbot"): 그래프의 시작 노드를 지정합니다. 첫 노드는 “chatbot”으로 설정하여, 맨 처음에 LLM이 사용자 질문을 처리하도록 합니다.compile(): 그래프 정의를 컴파일하여 실행 가능한 객체graph를 얻습니다.
이로써 LangGraph를 사용한 대화 흐름 정의가 완료되었습니다. 이제 graph 객체에 초기 상태를 넣어 실행하기만 하면, LangGraph가 알아서 LLM과 도구 호출 흐름을 관리해줄 것입니다.
✅ 확인: 지금까지 작성한 코드로 그래프를 시각화하면 다음과 같은 흐름입니다:
START -> chatbot -> (tools_condition=true) -> tools -> chatbot -> ... (반복)... -> (tools_condition=false) -> END
START에서chatbot으로 시작하고, chatbot에서 toolsCondition에 따라 tools로 갈 수도 있고 바로 END로 종료될 수도 있습니다. tools를 거치면 다시 chatbot으로 돌아와 루프를 형성합니다.
이러한 그래프 구조가 우리가 의도한 “LLM -> 필요시 도구 -> 다시 LLM -> … -> 종료” 흐름과 일치하는지 스스로 설명해보세요.
7단계: 챗봇 실행 및 테스트
마지막으로, 완성된 대화 그래프에 사용자 질문을 넣어서 실행해보고 결과를 확인해보겠습니다.
먼저 하나의 예시 질문으로 초기 상태를 구성합니다. 그리고 graph.invoke()를 통해 그래프를 실행합니다:
from langchain_core.messages import HumanMessage
# 초기 상태 설정: 사용자 질문 입력
initial_state: State = {
"messages": [HumanMessage(content="대전을 대표하는 빵집은?")],
"search_query": None,
"search_results": None
}
# 그래프 실행하여 결과 얻기
final_state = graph.invoke(initial_state)
initial_state["messages"]에HumanMessage(content="...")객체를 넣었습니다. 여기서는 “대전을 대표하는 빵집은?” 이라는 질문입니다. 이 메시지가 대화의 첫 메시지 (사용자 메시지)로서 역할을 합니다.graph.invoke(initial_state): 초기 상태를 넣어 그래프를 실행합니다. LangGraph는 설정된 흐름에 따라 노드들을 진행시켜 최종 상태를 반환합니다. 반환된 것을final_state에 저장하였습니다.
이제 final_state에는 상태의 모든 필드가 채워져 있을 것입니다. 특히 final_state["messages"] 리스트에는 대화에 참여한 메시지 객체들이 순서대로 들어있습니다. 이를 순회하며 내용을 출력해 봅시다:
from langchain_core.messages import AIMessage, ToolMessage
for msg in final_state["messages"]:
if isinstance(msg, HumanMessage):
print("👤 사용자:", msg.content)
elif isinstance(msg, AIMessage):
print("🤖 챗봇:", msg.content)
if msg.tool_calls:
# AI 메세지에 도구 호출 정보가 있을 경우
for call in msg.tool_calls:
print(f" ↪ (도구 요청: {call['name']} {call['args']})")
elif isinstance(msg, ToolMessage):
# 도구 실행 결과 메시지
print(f"🔧 도구[{msg.name}] 결과:", msg.content)
출력되는 로그를 통해 챗봇이 어떤 과정을 거쳤는지 알 수 있습니다:
- 사용자 메시지는 그냥 사용자가 말한 내용입니다.
- 챗봇(AI) 메시지는 모델이 생성한 응답으로, 만약 이 안에
tool_calls정보가 있다면, 챗봇이 그 시점에 도구 사용을 시도했다는 것을 나타냅니다. (어떤 도구를 어떤 인자로 호출했는지 함께 출력) - 도구 메시지는 실제 도구 함수가 반환한 결과입니다.
msg.name으로 어떤 도구의 결과인지 알 수 있고,msg.content에 사람이 읽을 수 있는 형태의 결과가 담겨있습니다. (extract_keyword의 경우 키워드 문자열,kakao_place_search의 경우 JSON 비슷한 문자열일 수 있습니다.)
예를 들어, 예상 출력의 한 시나리오를 보면:
👤 사용자: 대전을 대표하는 빵집은?
🤖 챗봇: 사용자의 질문을 이해했습니다. 검색을 진행합니다.
↪ (도구 요청: extract_keyword {'user_request': '대전을 대표하는 빵집은?'})
🔧 도구[extract_keyword] 결과: 대전 빵집
🤖 챗봇: '대전 빵집'으로 검색해볼게요.
↪ (도구 요청: kakao_place_search {'query': '대전 빵집'})
🔧 도구[kakao_place_search] 결과: [{'name': '성심당', 'address': '대전 ...', 'url': 'http://...'}, ...]
🤖 챗봇: 대전을 대표하는 빵집으로 성심당이 유명합니다. (중략)
위 시나리오를 해석해보면:
- 챗봇이 우선 사용자의 질문을 받고 “이해했고 검색하겠다”는 취지의 응답을 생성하면서 동시에
extract_keyword도구를 호출했습니다. - ToolNode가
extract_keyword("대전을 대표하는 빵집은?")을 실행하여 결과로"대전 빵집"을 추출했고, 그 결과가 ToolMessage로 대화에 추가되었습니다. - 챗봇이 다시 제어권을 가져와 이 키워드를 보고, Kakao API를 쓰겠다는 응답과 함께
kakao_place_search도구를 호출했습니다. - ToolNode가
kakao_place_search("대전 빵집")을 실행하여 상위 5개 검색 결과를 가져왔고, 그 JSON 형태의 결과가 ToolMessage로 추가되었습니다. - 마지막으로 챗봇이 이 결과를 받아 사용자에게 최종 답변을 구성했습니다 (예: 성심당이라는 빵집을 소개).
- 더 이상 도구가 필요 없으므로 대화가 종료되었습니다.
이 일련의 과정이 LangGraph를 통해 자동으로 이뤄졌습니다! 여러분은 사용자 질문만 넣으면, LLM이 알아서 적절한 순서로 도구를 호출하고 답을 찾아준 것입니다.
이제 다른 질문들도 넣어보면서 챗봇을 테스트해보세요. 예를 들어:
initial_state["messages"] = [HumanMessage(content="서울에서 애견동반 가능한 카페 알려줘")]
final_state = graph.invoke(initial_state)
# 위와 같은 방법으로 final_state["messages"]를 출력하여 확인
이런 입력에 대해 챗봇이 어떤 키워드를 뽑고, Kakao API에서 어떤 결과를 가져오며, 최종 답변을 어떻게 하는지 관찰해보세요.
또한, 현재 구조는 한 번 질문에 한 번 답변을 하는 형태지만, final_state를 다음 질문의 초기 상태로 넘기면 대화의 연속성을 가질 수도 있습니다. 다만 도구 호출에 대한 상태(search_query, search_results)를 초기화하거나 유지하는 전략이 필요합니다.